
The field of Machine Learning (or Artificial Intelligence how it’s often referred to by mainstream media) is evolving rapidly, understanding neural networks and the underlying workings of the current models is beyond the scope of this course.
In this unit we are looking at some of the most common uses of AI through a series of art projects.
Computer vision: image detection, tracking and recognition
Detecting, recognizing, and tracking objects in digital images, in particular bodies and faces, is one of the most common applications of ML. Why is that?
How are these projects approaching this problematic technology?
Cheese by Christian Moeller (2003)
Insecurity camera by Silvia Ruzanka, Ben Chang, Dmitry Strakovsky (2003)
Backlash by Grey Cake (2023)
Automatic anonymization of protesters.
Data Analysis
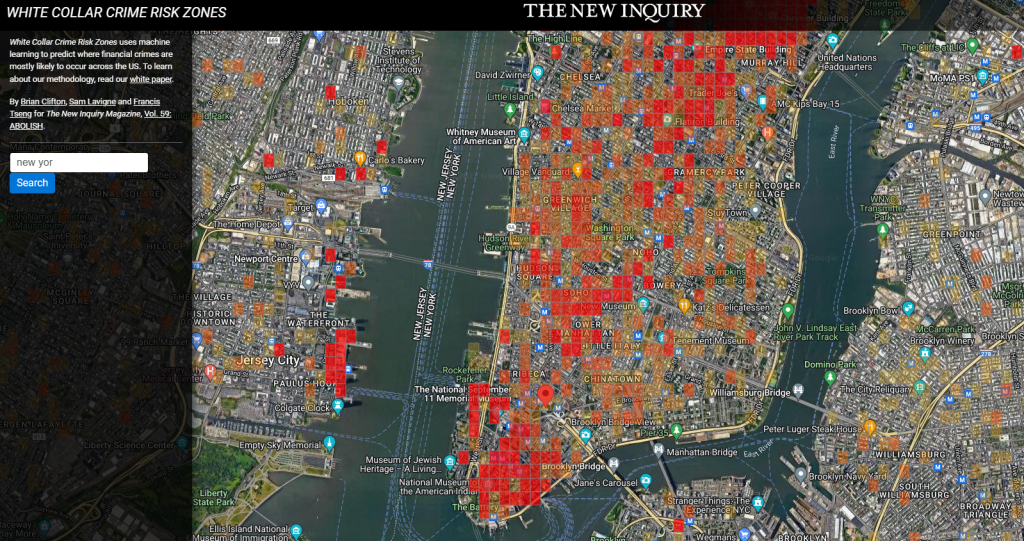
White Collar Crime Risk Zones by Brian Clifton, Sam Lavigne and Francis Tseng (2017)
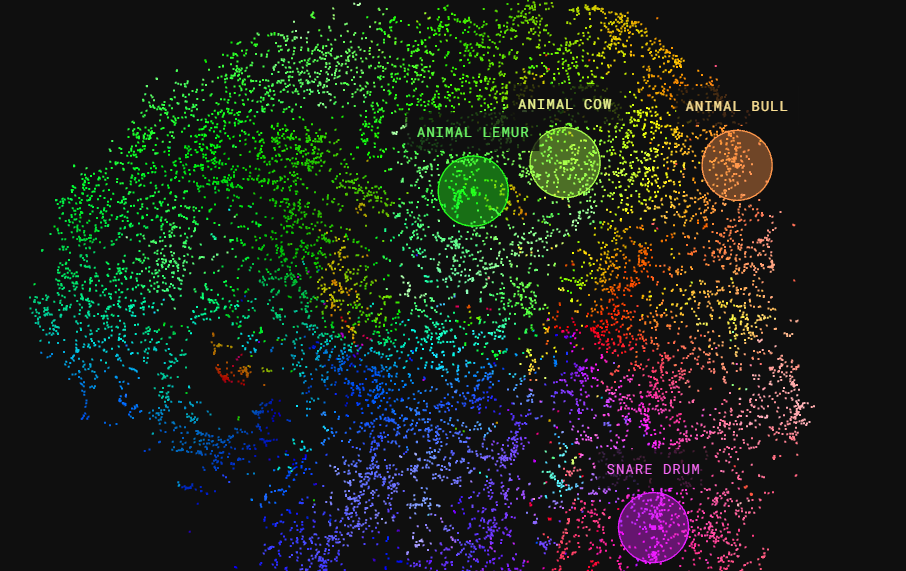
The Infinite Drum Machine by Kyle McDonald, Manny Tan, Yotam Mann, and friends at Google Creative Lab (2016)
A more scientific application of the same system Bird Sounds
Voice and text generation
Beyond chatbots
Conversations with Bina48 by Stephanie Dinkins (2014 – Ongoing)
Dinkins recorded her conversations with BINA48, an early chatbot modeled after a middle-aged black woman. Dinkins mirrors Bina48 while they discuss identity and technological singularity.
Kyle McDonald & Lauren Lee McCarthy (2023)
Voice In My Head explores the implications for AI (ChatGPT) to listen and intervene in your social experience in real-time, augmenting your personality. The piece begins with an onboarding session where you place a bud in your ear and the voice asks you to reflect on the inner voice you were born with. What if it could be more caring? Less obsessive? Less judgmental? More helpful? What if you could change your inner monologue?
As you respond to the onboarding questions, it clones the sound of your voice and uses it to speak to you. Then you go out into the world, as the voice follows along and offers commentary and direction. The resulting performance calls into question how natural vs synthetic each person’s thoughts actually are. Do any of us have our own point of view?

Shell Song by Everest Pipkin (2020)
Shell Song is an interactive audio-narrative game which explores deep-fake voice technologies and the datasets that go into their construction. By considering physical and digital bodies and voices, it asks what a voice is worth, who can own a human sound, and how it feels to come face to face with a ghost of your body that may yet come to outlive you. The piece reminds us that data is people, both in representations of data that is collected but also tools built by people to collect this data.
Image Generation
For an initial contrast, let’s consider this generative 1974 plotter artwork by computer arts pioneer, Vera Molnár, below. How did she create this artwork? We might suppose there was something like a double-for-loop to create the main grid; another iterative loop to create the interior squares; and some randomness that determined whether or not to draw these interior squares, and if so, some additional randomness to govern the extent to which the positions of their vertices would be randomized. We can suppose that there were some parameters, specified by the artist, that controlled the amount of randomness, the dimensions of the grid, the various probabilities, etc.

As with ‘traditional’ generative art (e.g. Vera Molnár), artists using machine learning (ML) continue to develop programs that render an infinite variety of forms, and these forms are still characterized (or parameterized) by variables. What’s interesting about the use of ML in the arts, is that the values of these variables are no longer specified by the artist. Instead, the variables are now deduced indirectly from the training data that the artist provides. As Kyle McDonald has pointed out, machine learning is programming with examples, not instructions.
The use of ML typically means that the artists’ new variables control perceptually higher-order properties. (The parameter space, or number of possible variables, may also be significantly larger.) The artist’s job becomes one of selecting or creating training sets, and deftly controlling the values of the neural networks’ variables.
-from Golan Levin’s lecture
This installation by alumni Aman Tiwari and Gray Crawford uses gestural control to give the user a bodily awareness of this multidimensional visual space.
BMO lab (2023)
Real-time Generation of Panoramic scenes from Voice using a custom Stable Diffusion pipeline
![]()
Emergent Forms by James Bettney (2024)
“a photorealistic pencil drawing of a hand grenade on a pristine white background” which generate an initial set of AI-produced images. One image is randomly selected as the seed for the next iteration. The AI then regenerates this image, producing new variations. This process repeats, with each cycle drifting further from the original concept.

Paragraphica by Bjoern Karmann (2023)
Context-to-image
See also similar works examining AI image making in relation to photography: Blind Camera (sound-to-image) by Diego Trujillo Pisanty, Black Box Camera (image-to-text-to-image), and Memogram (image-to-text)

The Big Smoke by Beatrice Lartigue (2023)
The series of “photographs” visualize invisible air pollution in Paris by using the color code of the forecast maps to modulate the tint of the smoke clouds (cold/good > hot/extremely bad). The project mines air quality data, through an overall index including ozone, nitrogen dioxide, particulate matter and fine particles.

Promptography by Boris Eldagsen
Introspections
Blind looking for a mirror
Pseudomnesia
Professional Development
Eldagsen caused controversies after winning a prestigious photography prize with an AI generated image.
Another artist won an AI photography competition with a real photo.
 Igun: prototype X by Minne Atairu (2024-)
Igun: prototype X by Minne Atairu (2024-)
The 1897 British invasion of Benin had a devastating effect on its rich artistic landscape, resulting in a 17-year (1897-1914) artistic recession – a period which lacks visual/archival records. Igùn generates models that might have been created in this period.
Video Generation
Learning to See by Memo Atken (2017)
“An artificial neural network looks out onto the world, and tries to make sense of what it is seeing. But it can only see through the filter of what it already knows. Just like us. Because we too, see things not as they are, but as we are.”

Fighting Windmills by Addie Wagenknecht (2023)
The artist as a deepfake confronts a deepfaked doppelgänger in a boxing ring, symbolizing the internal battle against self-sabotage and the weight of imposed standards.

Posthuman Cinema by Mark Amerika, Will Luers & Chad Mossholder (2023)
Dataset Bias
Read Excavating AI by Kate Crawford and Trevor Paglen

Deep Hysteria by Amy Alexander
The people in these artworks are “AI”-generated twins that vary in gender presentation. Another “AI,” trained on human perceptions, identifies the emotion on their faces.

Unbroken Meaning is a Black Corpus project that investigates the ability of current speech-to-text algorithms to understand African Diaspora-derived Creole, Pidgin, and Broken English. It seeks to demonstrate the bias of these algorithms while developing new algorithms that are better suited to recognize phrases and languages of these communities. Additionally, it seeks to create suitable text-to-speech methods for proper computer pronunciation of these languages.
Black Corpus by Ayodamola Tanimowo Okunseinde Series of projects and artworks that attempt to build datasets and tools centered on black culture.
Various types of racial and gender bias have been affecting AI systems since their inception.
Also see Stable diffusion bias explorer
 Prompt: Guy with swords pointed at me meme except they are Homer Simpson.
Prompt: Guy with swords pointed at me meme except they are Homer Simpson.
DALL-E3 attempts to combat the racial bias in its training data by occasionally randomly inserting race words that aren’t white into a prompt.

Object recognition affected by skin color.
 The viral AI avatar app Lensa undressed me—without my consent
The viral AI avatar app Lensa undressed me—without my consent
My avatars were cartoonishly pornified, while my male colleagues got to be astronauts, explorers, and inventors.
By Melissa Heikkilä
Part of the problem is that these models are trained on predominantly US-centric data, which means they mostly reflect American associations, biases, values, and culture, says Aylin Caliskan, an assistant professor at the University of Washington.
–MIT Technology Review
Beyond media representation why this matters?
Flawed facial recognition system sent a man to jail
Predictive policing
AI used to deny health insurance and to appeal such denials
AI tool used to predict the need of extra medical care is biased against Black patients
AI-powered recruiting tool is biased against women (luckily scrapped by Amazon)
AI tools are used to grade student essays
AI tools are used to review college admissions